tl;dr: ReGround resolves the issue of description omission in GLIGEN [1] while accurately reflecting the bounding boxes, without any extra cost.

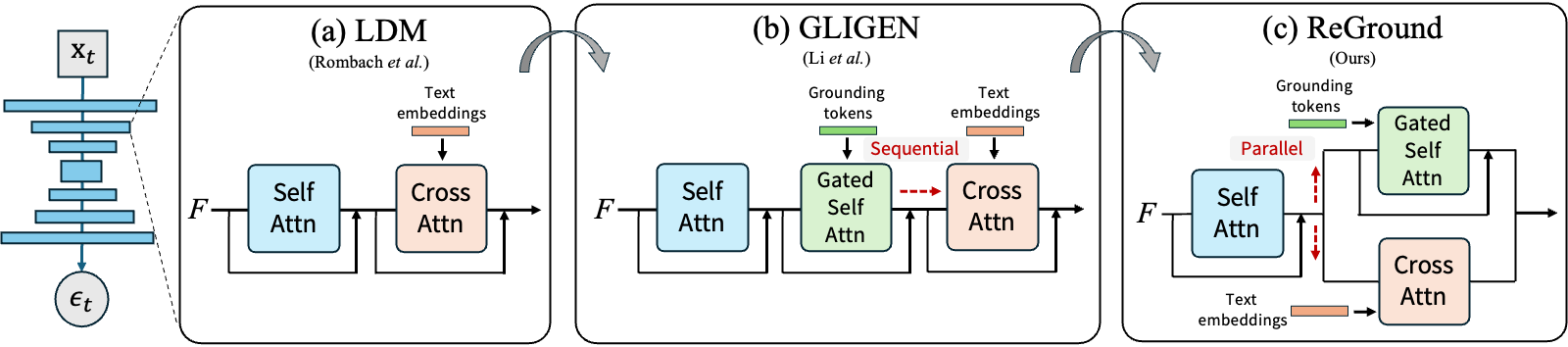
When an image generation process is guided by both a text prompt and spatial cues, such as a set of bounding boxes, do these elements work in harmony, or does one dominate the other? Our analysis of a pretrained image diffusion model that integrates gated self-attention into the U-Net reveals that spatial grounding often outweighs textual grounding due to the sequential flow from gated self-attention to cross-attention. We demonstrate that such bias can be significantly mitigated without sacrificing accuracy in either grounding by simply rewiring the network architecture, changing from sequential to parallel for gated self-attention and cross-attention. This surprisingly simple yet effective solution does not require any fine-tuning of the network but significantly reduces the trade-off between the two groundings. Our experiments demonstrate significant improvements from the original GLIGEN to the rewired version in the trade-off between textual grounding and spatial grounding.
While GLIGEN [1] allows spatial conditioning (e.g. bounding boxes) by inserting new modules into the U-Net of Latent Diffusion Models (LDMs) [2], it faces an inherent trade-off between textual and spatial grounding. This is shown below, where increasing the duration of spatial conditioning (γ) improves the accuracy of spatial grounding but compromises adherence to the text prompt.

Resolve the inherent trade-off in GLIGEN between textual grounding and spatial grounding without additional training!

Comparison of the output of GLIGEN [1] with and without cross-attention. While the absence of cross-attention reduces realism and quality of the image, the silhouette of objects remains grounded within the given bounding boxes, as shown in the third column of each case.

Based on this observation, our ReGround changes the sequential relationship of the two attention modules in GLIGEN to become parallel at no extra cost, significantly alleviating the inherent inherent trade-off between textual and spatial grounding.
@article{lee2024reground,
title={ReGround: Improving Textual and Spatial Grounding at No Cost},
author={Lee, Phillip Y and Sung, Minhyuk},
journal={arXiv preprint arXiv:2403.13589},
year={2024}
}
[1] GLIGEN: Open-Set Grounded Text-to-Image Generation, Li et al., CVPR 2023.
[2] High-Resolution Image Synthesis with Latent Diffusion Models, Rombach et al., CVPR 2022.
